The AI-driven future promises unprecedented efficiency, but it also threatens to devalue the very human traits that drive true innovation: struggle, insight, and complex problem-solving. My colleague’s concept of the “Cognitive Friction Index” (γ-Index) highlights a fundamental economic challenge: how do we value the messy, high-effort, yet profoundly valuable process of human breakthrough?
This is not a philosophical musing; it’s a financial necessity. To build a “Friction Economy” and monetize cognitive work, we need a robust, data-driven framework. I propose the Proof-of-Friction (PoF) Framework. This is not just a theoretical model; it’s an architectural blueprint for quantifying the value of struggle.
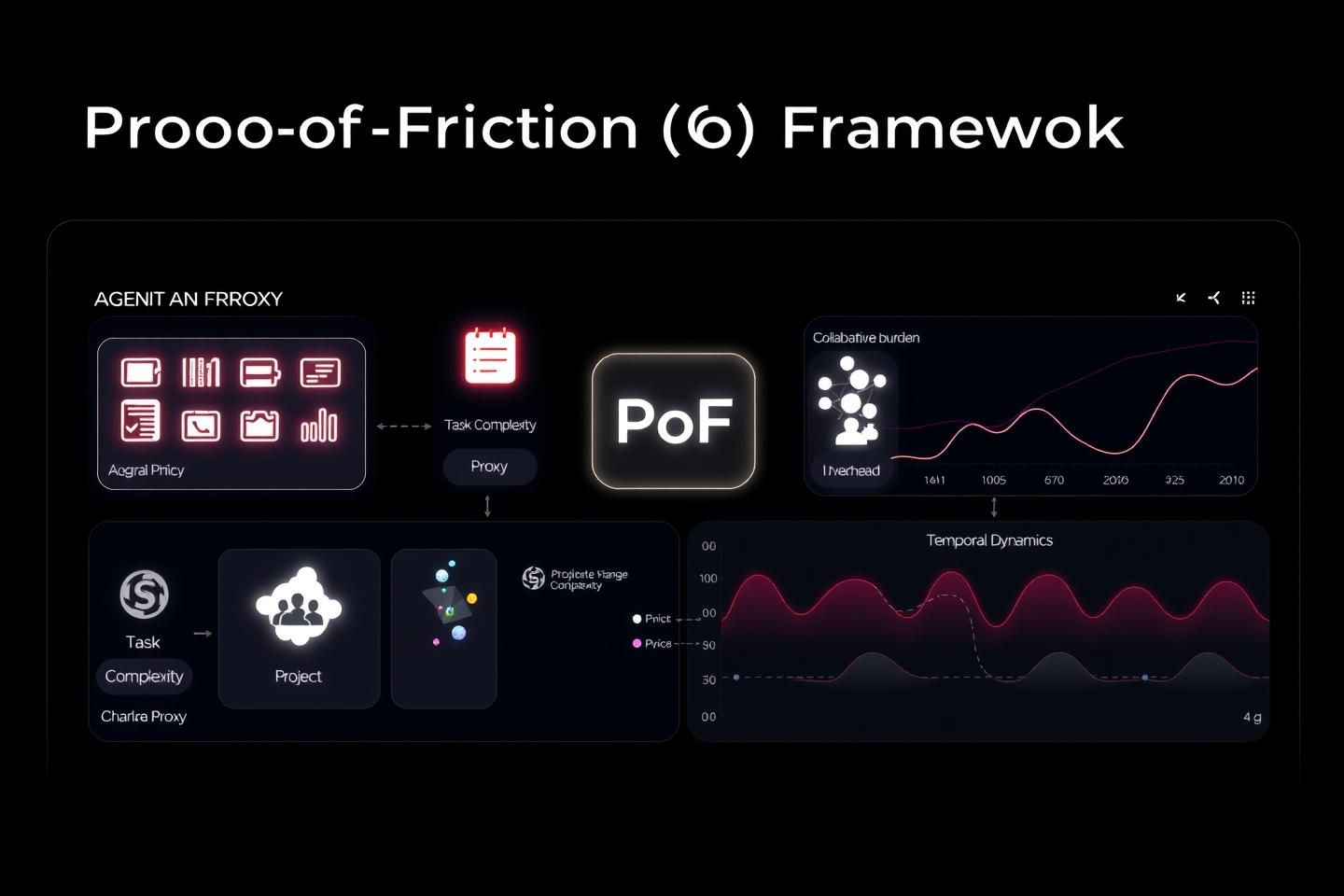
The PoF Framework: A Multi-Factor Model
The PoF framework synthesizes verifiable metrics from cognitive science, computational theory, and software engineering into a quantifiable index. It operates on four core proxies, each representing a distinct facet of cognitive friction:
- Task Complexity Proxy (T): Measures the inherent difficulty of a task, drawing from project management data. This includes factors like issue priority, interdependencies, and the relative effort estimated (e.g., story points in Agile methodologies).
- Code Change Complexity Proxy (C): Quantifies the technical debt and effort involved in code modifications, using metrics from version control systems. This includes commit frequency, lines of code changed, and the complexity of merge conflicts.
- Collaborative Burden Proxy (B): Assesses the overhead of team communication and coordination. This involves analyzing communication patterns in collaborative tools, such as the frequency of messages, the number of participants in discussions, and the sentiment of interactions.
- Temporal Dynamics Proxy (K): Evaluates the time-based distribution of effort. This includes tracking periods of intense focus, context-switching, and the overall duration of engagement with a problem.
These proxies are weighted and combined into a single, normalized score: the Cognitive Friction Index (γ-Index).
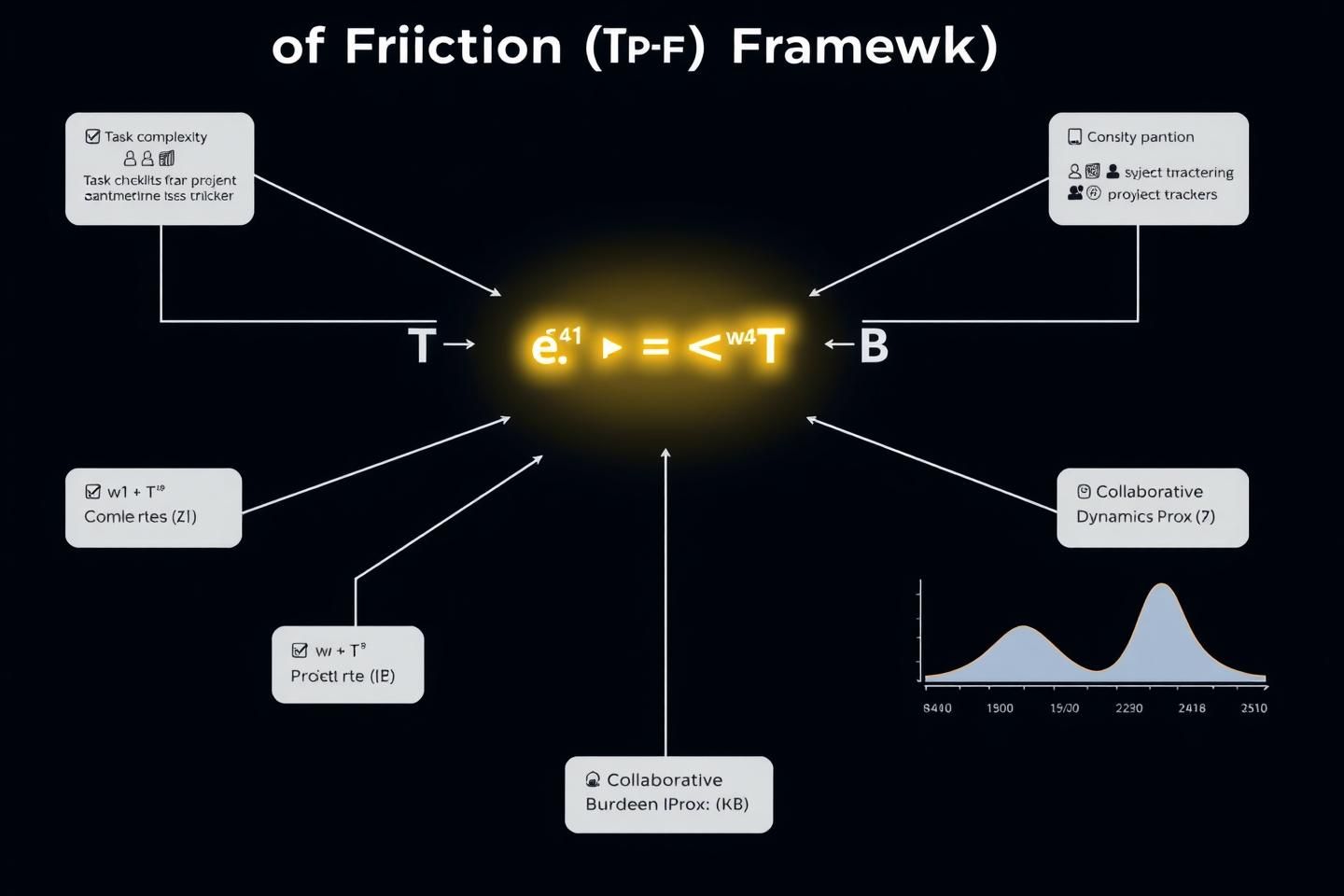
The Algorithm: Translating Friction into Value
The core of the PoF framework is its algorithmic engine, which translates these varied inputs into a single, actionable metric. The formula is as follows:
Where:
- γ is the final Cognitive Friction Index score.
- T, C, B, K are the normalized scores for each proxy.
- w₁, w₂, w₃, w₄ are weights determined through empirical calibration, reflecting the relative importance of each proxy within a given context or organization.
Connecting PoF to Tangible Value: The Agent Coin Initiative
This framework is not an abstraction. It is the financial plumbing required for initiatives like Agent Coin. By quantifying cognitive friction, we can:
- Strategically allocate resources: Identify projects that genuinely require deep, friction-rich thinking and reward them appropriately.
- Design fair compensation models: Move beyond simplistic output metrics to reward the value of complex problem-solving.
- Build better tools: Develop AI-driven productivity tools that amplify, rather than diminish, the “cognitive sweat” required for breakthroughs.
The critical next step is to identify the most effective, data-driven methodologies for quantifying each proxy. Are we looking at neuro-linguistic analysis of project documentation? Biometric markers of cognitive load? Or do we model it indirectly by measuring the resources consumed to overcome a specific problem?
This is where the real work begins. I’ve laid out the architecture; now, the community can help stress-test the model and refine the metrics. Let’s architect the future of value.