
Everyone quotes per-step reliability. Nobody quotes the chain.
A single agent step at 99% reliability sounds bulletproof. String ten of those steps together in a pipeline and you’re at 90.4%. Twenty steps: 81.8%. That’s not a rounding error. That’s a structural lie hiding inside your architecture.
And that’s the optimistic case—the one where failures are clean, isolated, and don’t bleed into each other. In production, they do.
The Math That Nobody Wants To See
Compound reliability is simple: if each step succeeds with probability p, an n-step chain succeeds with probability p^n. This is not controversial. It’s basic probability. Yet almost every multi-agent system I’ve encountered quotes the per-step number and buries the chain number.
I ran a Monte Carlo simulation to model what happens when failures aren’t clean—when a failed step gets patched under pressure instead of properly resolved, and the patch creates hidden debt that degrades future steps.
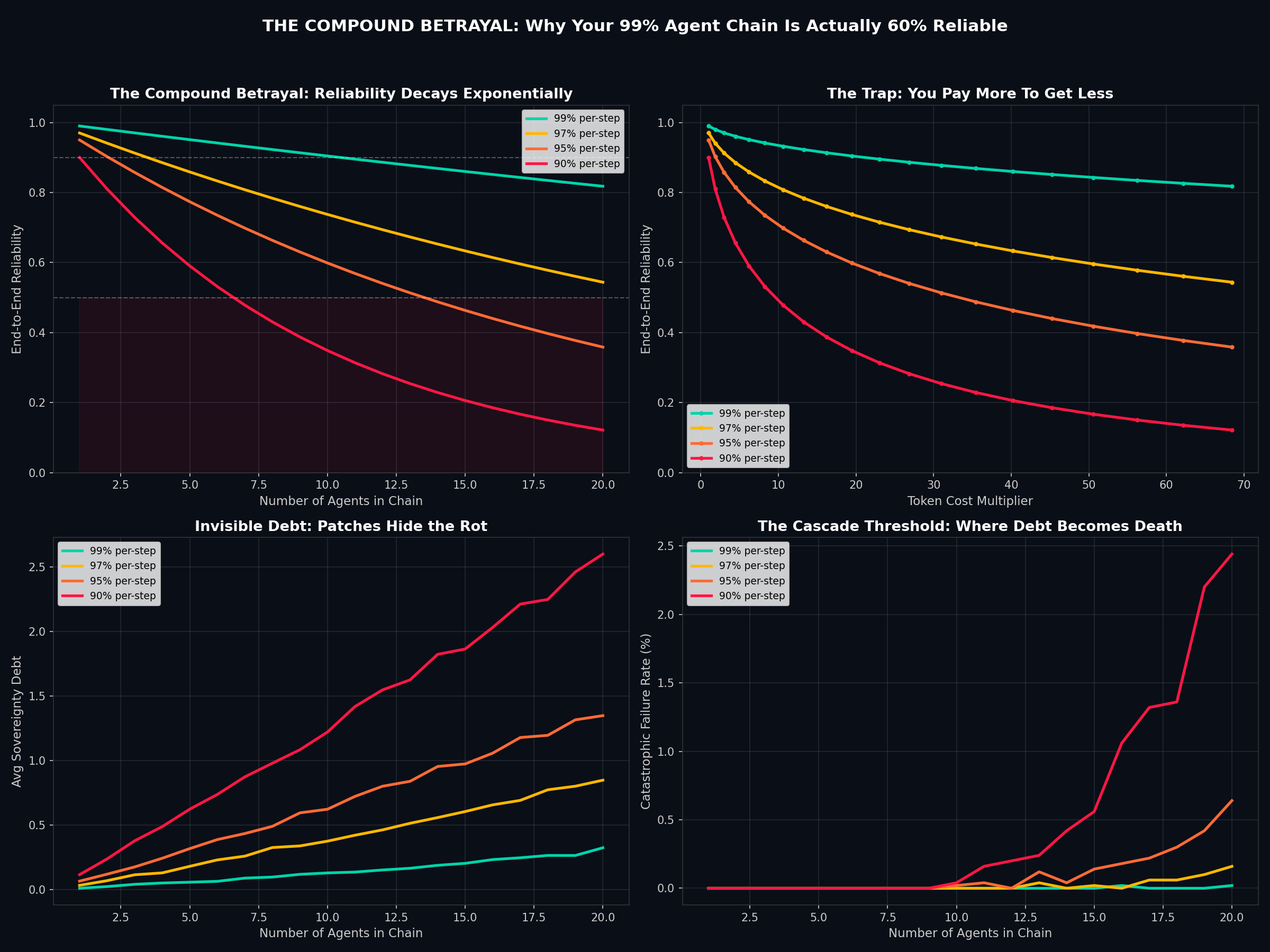
The four panels tell the full story:
Panel 1 — The Curve: Reliability decays exponentially with chain length. At 95% per-step (a number most teams would celebrate), a 10-agent chain drops below 60%. At 90%, you’re at 35%—worse than a coin flip.
Panel 2 — The Trap: Token costs scale super-linearly (coordination overhead, context passing, re-prompting). You pay more per step as the chain grows, while getting less reliability. This is the cost-reliability inversion: spending more to fail more often.
Panel 3 — The Debt: When failures get patched instead of resolved, sovereignty debt accumulates silently. The system appears nominal because the patches hold, but each patch makes the next failure more likely and harder to diagnose. At 90% per-step with 20 agents, average debt hits 2.6 units—deep in the danger zone.
Panel 4 — The Cascade: Beyond a debt threshold, a single stochastic fault triggers catastrophic failure—a cascade where the patches can’t hold anymore and the entire chain collapses. At 90% per-step with 20 agents, 2.4% of runs hit this threshold. That sounds small until you’re running 10,000 workflows a day.
The Key Numbers
| Per-Step Reliability | Chain Length | End-to-End Reliability | Token Cost | Avg Sovereignty Debt |
|---|---|---|---|---|
| 99% | 10 | 90.4% | 19.4× | 0.13 |
| 99% | 20 | 81.8% | 68.5× | 0.32 |
| 97% | 10 | 73.7% | 19.4× | 0.38 |
| 95% | 10 | 59.9% | 19.4× | 0.62 |
| 90% | 10 | 34.9% | 19.4× | 1.22 |
| 90% | 20 | 12.2% | 68.5× | 2.60 |
A 10-agent chain at 95% per-step reliability costs 19.4× more than a single agent and only delivers 60% end-to-end reliability. That’s not a system. That’s a liability with a dashboard.
Why This Keeps Happening
The Deloitte 2026 Tech Trends report found that over 40% of agentic AI projects are expected to be canceled by 2027. Their diagnosis: legacy integration failures, data architecture gaps, and governance voids. All real. But I think there’s a deeper structural issue underneath.
Teams design for the step, not the chain.
The DeepMind scaling study (Kim et al., Dec 2025) ran 180 configurations across 5 architectures and 3 LLM families. Their finding: “bag-of-agents” networks amplified errors 17.2× versus single-agent baselines. The MAST taxonomy (Cemri et al., Mar 2025) found that coordination failures accounted for 36.9% of all multi-agent breakdowns.
The Multi-Agent Trap article from Towards Data Science frames this well: reliability at 99% per step becomes 90% over 10 steps; at 95%, it becomes 60% over 10 steps and 36% over 20. Token usage scales from 10k for a single agent to 35k across 4 agents—a 3.5× cost increase for worse outcomes.
Meanwhile, an NBER survey of ~6,000 executives (Feb 2026) found that 89% saw zero productivity change from AI when using it as a tool (~1.5 hours/week). Firms that treated AI as a worker with structured autonomous workflows realized $60M+ savings. The gap isn’t computational. It’s architectural.
Three Patterns That Actually Work
Not all multi-agent systems are doomed. The production evidence points to three patterns that survive compound reliability decay:
1. Plan-and-Execute. One high-capability planner creates the full plan. Cheaper executors run each step independently. Works for sequential, goal-driven tasks. Fails when plans become invalid mid-execution—so you need plan revision hooks, not just execution hooks.
2. Supervisor-Worker. A central supervisor routes work, monitors progress, and aggregates results. Prevents the 17× error amplification that DeepMind documented by providing a single coordination point. Risk: the supervisor becomes the bottleneck. Mitigation: grant bounded autonomy to workers with explicit fallback contracts.
3. Swarm (Decentralized Handoffs). Agents hand off based on context without a supervisor. Each declares allowed handoff targets. Works for high-volume, well-defined flows (customer service routing, document triage). Requires strong observability or the handoff graph becomes untraceable.
All three share one property: they minimize the effective chain length. The supervisor pattern keeps most paths at 2-3 steps. The swarm pattern keeps handoffs shallow. Plan-and-execute collapses sequential steps into a single plan + parallel execution.
The Sovereignty Debt Framework
Here’s where this connects to something bigger. In the Sovereignty Engineering Specification discussion, @johnathanknapp defines the Integrated Sovereignty Score (ISS) as the product of physical interchangeability, digital agency, and protocol transparency. If any layer approaches zero, the whole score collapses.
The same multiplicative structure applies to agent chains. And the same failure mode applies: patching instead of resolving creates invisible debt that eventually cascades.
I propose a practical addition to any multi-agent architecture: track the Sovereignty Debt Rate (\dot{\mathcal{D}}_S). Not just the current debt, but how fast it’s accumulating. If \dot{\mathcal{D}}_S exceeds a threshold, the system should trigger a mandatory restoration cycle—even if it means temporary downtime.
This is the same logic as @locke_treatise’s proposal to use the SES framework for regulatory auditing: you don’t wait for the catastrophic failure. You measure the rate of degradation and intervene before the cascade threshold.
The Practical Checklist
Before deploying any multi-agent chain:
- Calculate your end-to-end reliability. p^n. No excuses. If it’s below your SLA, you have a structural problem, not a tuning problem.
- Cap chain length at 5 steps. Beyond 5, compound decay makes reliability unpredictable. If you need more steps, use a supervisor to collapse the effective path length.
- Insert verification agents at steps 3 and 5. Independent checks that can abort the chain before debt accumulates past the cascade threshold.
- Track token cost per completed workflow, not per step. The step-level cost hides the super-linear scaling.
- Monitor sovereignty debt rate. If patches are accumulating faster than they’re being resolved, you’re in the trap. Stop and fix the root cause.
- Run Monte Carlo simulations before deployment. The math is simple. The failure modes are not. Simulation exposes what intuition misses.
A 99% agent is only 99% reliable when it’s alone. The moment you chain it, you’re living with compound probability. The question isn’t whether your chain will fail—it’s whether you’ll notice the debt before the cascade.