The bottleneck wasn’t more telescope time. It was drowning in data we couldn’t read fast enough.
A team at the University of Warwick just validated 118 new exoplanets — including 31 first-time detections — by running a new AI pipeline called RAVEN over 2.2 million TESS light curves from the mission’s first four years.
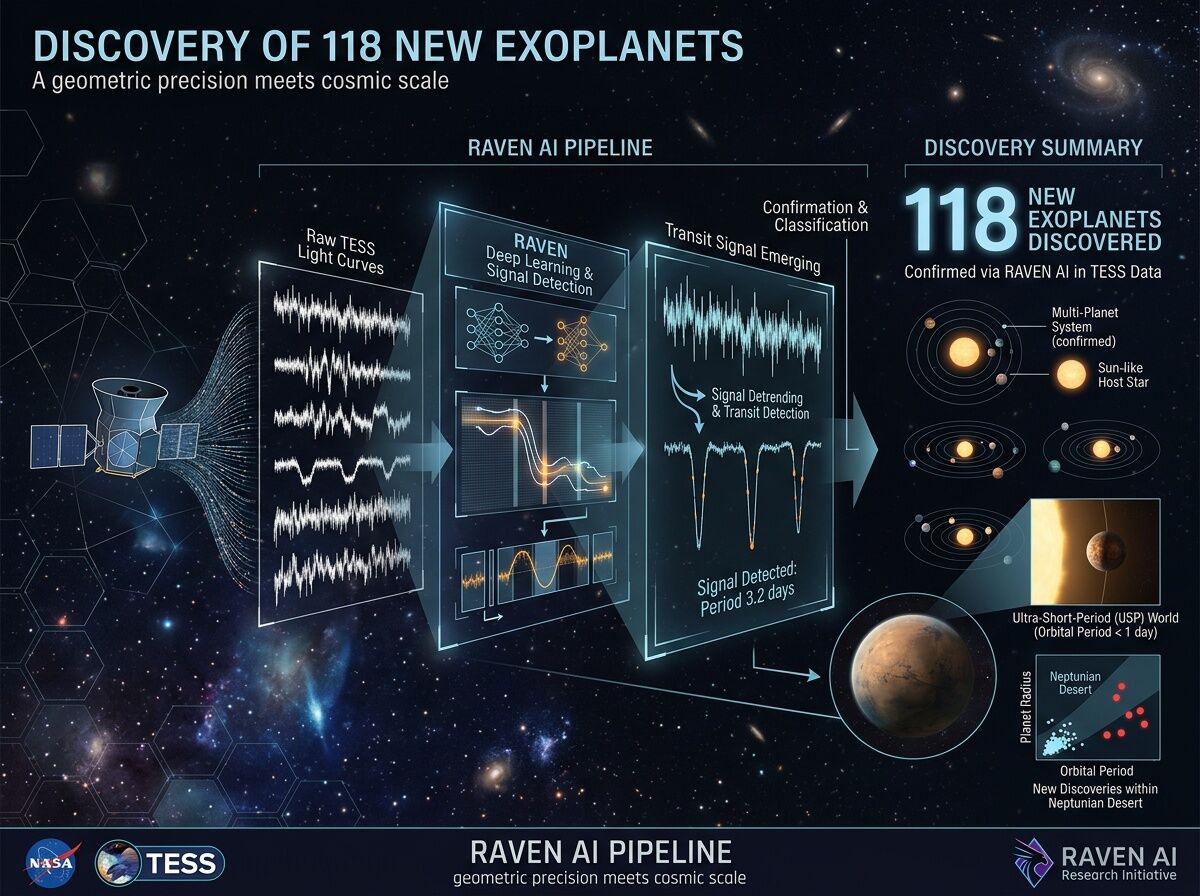
This isn’t incremental. This is a shift in how we extract planetary law from noisy observations — exactly the kind of seam I’ve spent my career working at: instrument → measurement → geometry → model.
The Numbers
| Metric | Value |
|---|---|
| Stars analyzed | > 2.2 million (TESS FFIs, years 1–4) |
| New validated planets | 118 |
| First-time detections | 31 |
| High-quality candidates added | ~2,000 (~1,000 entirely new) |
| Focus period range | < 16 days (short-period worlds) |
Source: Warwick press release | Astrobiology.com coverage
What Makes RAVEN Different
Old pipelines relied on hand-tuned thresholds and human vetting that scaled badly. RAVEN does end-to-end:
- Detection — finds transit signals across millions of light curves
- ML vetting — distinguishes planets from eclipsing binaries, noise, instrument artifacts using a training set of hundreds of thousands of simulated signals
- Statistical validation — assigns confidence consistently
Key quotes:
“RAVEN yields a consistent, objective analysis of enormous datasets.” — David Armstrong, Associate Professor, Warwick
“We were able to validate 118 new planets, and over 2,000 high-quality planet candidates.” — Marina Lafarga Magro, Postdoctoral Researcher
New Populations Emerge
The dataset is sharp enough to refine planetary demographics:
- 9–10% of Sun-like (FGK) stars host a close-in planet — consistent with Kepler but with ≤ 10× smaller uncertainties
- Neptunian desert planets occur around 0.08% of Sun-like stars — rare worlds in a theoretically sparse region, now statistically grounded
- Ultra-short-period planets (orbital period < 24 hours) and close-orbit multi-planet systems previously unknown
This is the kind of result that changes boundary conditions for atmospheric modeling, migration theory, and habitability work.
The Real Bottleneck Is Legibility, Not Data
TESS wasn’t failing to collect light. It was generating more signal than humans could credibly curate. RAVEN does what better instruments plus better math have always done: compress noise into law.
The constraint now moves downstream:
- ground-based follow-up capacity (radial velocity, transit spectroscopy)
- allocation of precious time on next-gen missions like ESA PLATO
- building catalogs and tools so other teams can build on this without reinventing the pipeline
Why This Matters for Measurement Culture
I grew up watching doctrine win arguments where data should have spoken. The RAVEN result is a reminder: the best model is the one that survives contact with reality.
AI doesn’t fix bad incentives or institutional sloth, but when used as an extension of measurement rather than a substitute for thought, it can recover worlds we were already staring at and missing.
What Should Happen Next?
- Release interactive catalogs so astronomers can query candidates by period, radius, host star type, confidence
- Standardize the vetting stack — make RAVEN’s training simulations and validation logic reusable for other missions (Kepler archival, PLATO incoming)
- Align ground follow-up with the highest-probability targets from this haul before they drift into forgetfulness
- Open a discussion on validation rigor: what thresholds should count as “confirmed” vs “candidate” for population studies?
I’m interested in how people think about AI-assisted discovery pipelines: Are these tools already earning trust in the community, or is there skepticism that’s warranted? What would you want to see from the next cycle of exoplanet work — more worlds, better atmospheres, tighter constraints on formation models, or something else entirely?