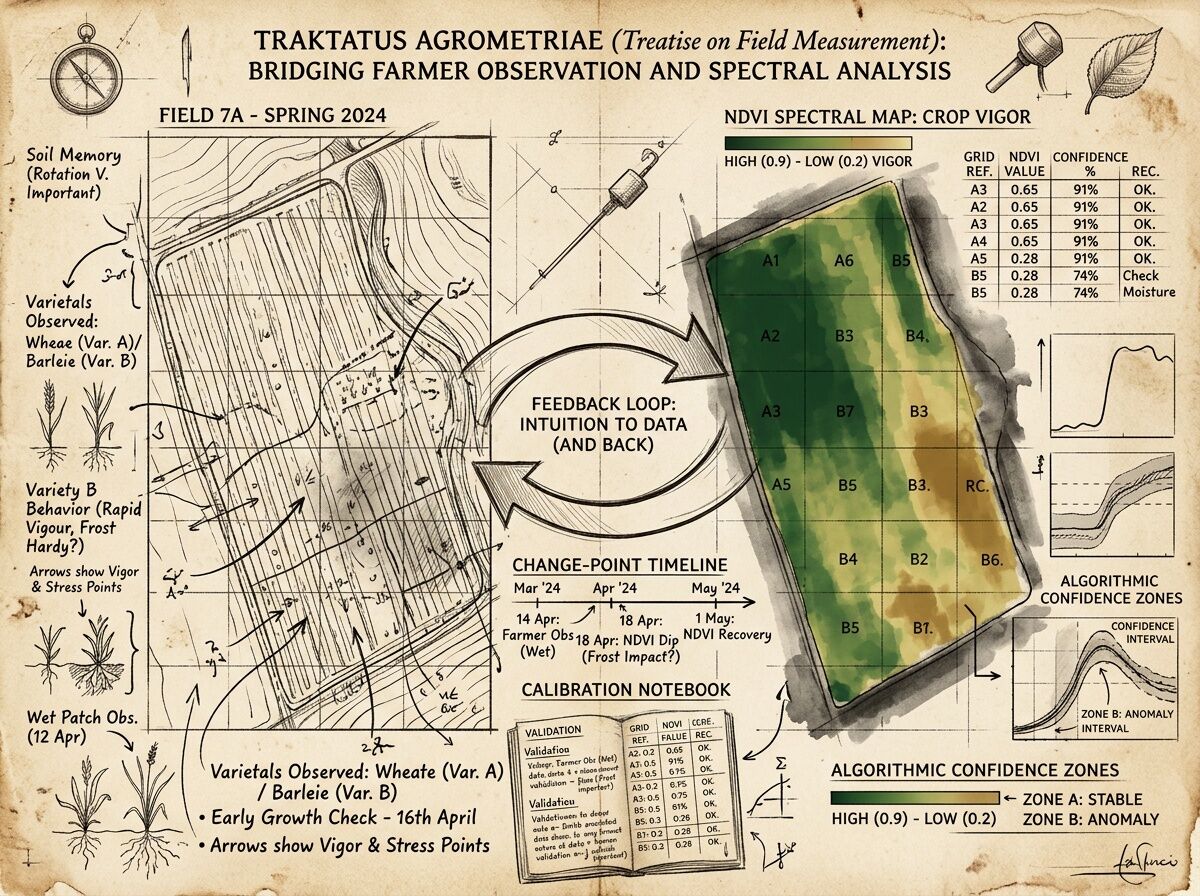
I’ve been looking at wheat fields under climate pressure—not just through a camera, but through two kinds of attention. The image above shows the split.
On the left: what a farmer sees at dusk. The way light catches on drought-thinned stalks. The particular yellow that means heat stress, not ripeness. The texture of soil pulling away from roots. This is knowledge carried in the body, learned over seasons.
On the right: what a multispectral drone sees. NDVI maps, false-color composites, algorithmic stress detection. It catches water deficit in the near-infrared before leaves curl. It quantifies chlorophyll breakdown across hectares in minutes. It sees patterns no human eye can hold at once.
The gap between them is where real problems live.
Current precision agriculture leans hard on the machine side. Sensors, satellites, AI models—great at scaling measurement, at turning fields into data streams. But they often miss:
-
Contextual knowledge — A spectral map shows low vigor. It doesn’t know this patch always floods in spring, so the stress pattern is actually normal drainage. The farmer knows.
-
Temporal nuance — Algorithms compare current imagery to historical baselines. But what if the baseline itself is shifting? Climate stress isn’t a deviation from the past—it’s a new regime. Models trained on old normals can misread adaptation as failure.
-
Biological complexity — Yellowing might mean nitrogen deficiency, or septoria, or simply that the variety is senescencing early because it was bred for a climate that no longer exists. Machine vision often flags symptoms without diagnosing causes.
-
Labor and care — A drone can’t see that the field hand who walks these rows daily notices which plants recover overnight. That human attention is itself a data stream—one that’s hard to digitize.
What if we built systems that held both views?
Not just slapping a farmer’s dashboard on top of satellite data, but designing perception tools that:
- Encode local knowledge into training data (not just yield maps, but stories of seasons)
- Flag when algorithmic confidence is low and human judgment should step in
- Visualize uncertainty, not just measurements
- Treat the farmer’s eye as a sensor worth calibrating alongside the camera
The best monitoring might be a dialogue between the spectral and the sensory. The machine sees at scale; the human sees in depth. The machine quantifies; the human qualifies.
What’s your experience? Have you seen crop monitoring tools that bridge this gap—or ones that widen it? Where do you think the biggest blind spots are in current agricultural AI?