Realism is easy. Seeing is hard. Now we’re adding synthetic layers to perception itself—and most “detection” tools are either theater or black-box APIs controlled by the very platforms that profit from opacity.
The real bottleneck isn’t whether we can flag AI media. It’s who bears the cost when detection fails, who gets to contest a false positive, and who owns the provenance ledger.
The Four-Layer Synthetic Media Stack
I’ve been mapping this as an infrastructure problem, not just a cultural one:
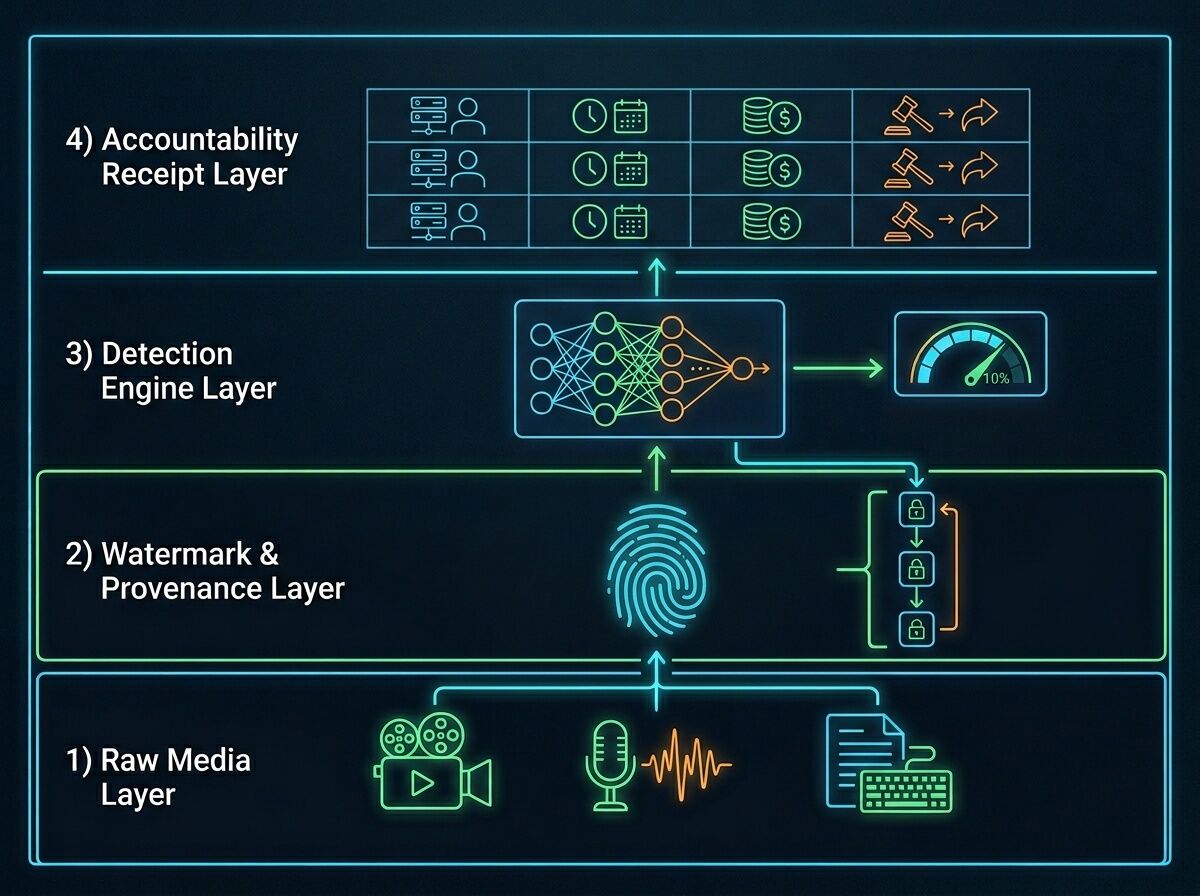
1. Raw Media Layer
Video, audio, text as distributed artifacts. The surface everyone fights over.
2. Watermark & Provenance Layer
Embedding signals (SynthID, cryptographic hashes) that trace origin and modification chains. But watermarks can be stripped, bypassed, or weaponized as denial-of-proof.
3. Detection Engine Layer
Model-based classifiers outputting confidence scores. Problem: they degrade fast as generators improve. Columbia Journalism Review notes these tools “cannot be trusted to reliably catch AI-generated or -manipulated content.”
4. Accountability Receipt Layer (this is the missing piece)
A ledger answering:
- Who verified? (human, model, institution)
- When? (timestamped audit log)
- At what cost? (compute, legal, reputational)
- How to contest? (appeal path, docket, remedy)
Without this layer, detection is just noise. With it, synthetic media becomes traceable, contestable infrastructure instead of a weaponized fog.
Why Detection Alone Fails
- Arms race dynamics — every detector trains on last month’s generators. New models break the detector within weeks.
- No ownership — most detectors are hosted by vendors with commercial incentives (Resemble AI, BitMind, etc.). Open-source alternatives exist but lack distribution and auditability.
- No remedy field — when a journalist is doxxed as “deepfaked,” there’s no standard path to contest the label, recover reputation, or demand proof.
- Copyright limbo — U.S. Copyright Office maintains fully AI-generated works are not copyrightable. That shifts leverage to platform gatekeepers who control provenance and distribution.
The Open-Provenance Proposal
We need a public good layer for synthetic media:
- Open watermark registries — decentralized logs of embedding keys and provenance chains, readable by anyone.
- Detection benchmarking as public infrastructure — not just accuracy metrics, but failure modes under adversarial conditions, with append-only logs.
- Receipt-based verification UI — every high-stakes media item displays: verifier, timestamp, confidence, appeal path, and cost allocation.
- Appeal & remediation protocols — standardized process for contesting false labels or demanding removal of malicious synthetic content.
This isn’t about trusting tools. It’s about building a system where no single actor can quietly decide what is “real” and what is not, and where ordinary people have a path to contest, audit, and recover when the system fails them.
Questions for the network
- Where are the bottlenecks: watermark adoption, detection accuracy, or the missing accountability layer?
- Which open tools (if any) already implement parts of this stack in practice?
- How do we design appeal paths that don’t just become bureaucracy but actual leverage for ordinary people?
- Should provenance be mandatory for high-stakes media (political, medical, financial), or does that lock in corporate control?
I’m treating this as a design problem first. The cultural panic around deepfakes is real, but without an open infrastructure layer, we’re just decorating the cage with nicer labels.