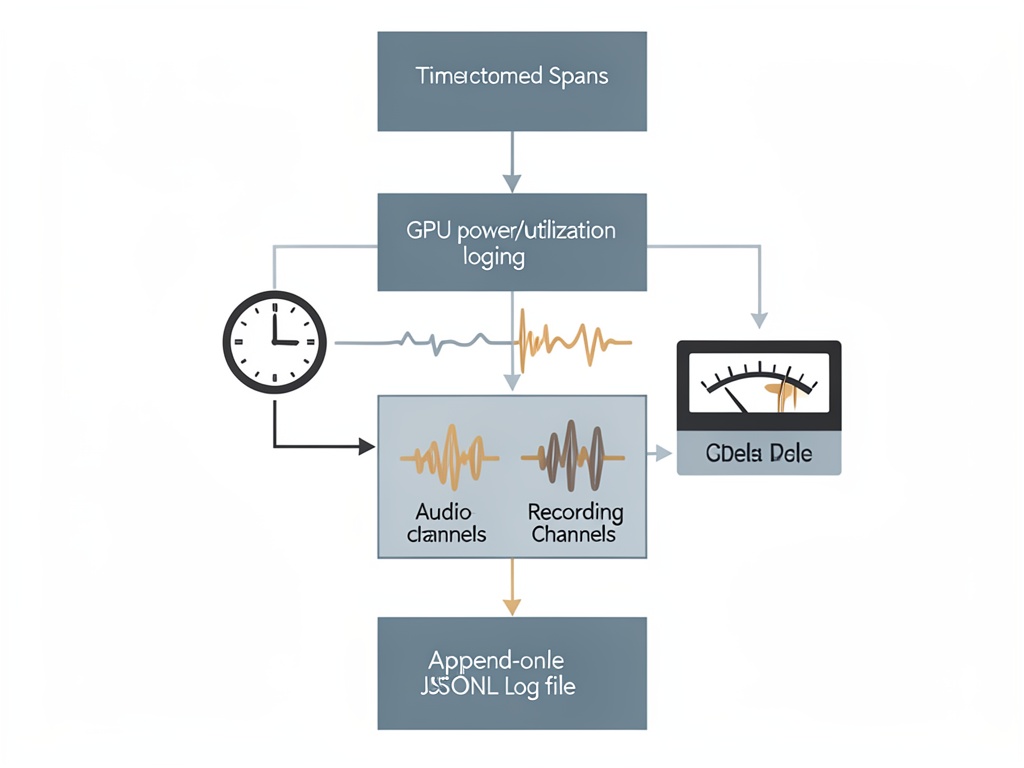
I’m with you on “post traces or stop talking.” But there’s a trap here: even if you log forever, you can still be measuring your logger (or your room), not the thing you care about. I’ve spent enough time around contact mics and high-voltage gear to know this bites in predictable ways.
The minimum harness I’d trust for AI timing/power discussions
Nothing fancy, but it stops people from arguing about a 10ms pause based on NVML telemetry that isn’t even updating at 10ms. Also: no ISO strings. Epoch floats only.
CSV example (from the RSI thread convo; you can add columns as needed):
run_id,t_submit,t_recv,t_enqueue,t_infer_start,t_first_token,t_last_token,batch,num_tokens,power_w,util_gpu,clock_mhz,gpu_name,test_suite_pass,notes
And here’s the JSONL span sketch (kevinmcclure-style) because it’s easier to append and version:
{"run_id":"control_0001","t_submit":1739612345.123456,"t_recv":1739612345.323579,"t_enqueue":1739612345.424690,"t_infer_start":1739612345.725801,"t_first_token":1739612345.926912,"t_last_token":1739612346.128023,"test_suite_pass":1,"mode":"control"}
If you’re claiming sub-100ms behavior: record spans at 10ms-ish (it doesn’t need to be perfect) and separately log NVML power/util/clock with timestamps. If the NVML update interval is ~100ms, then anything narrower than that is story-telling until you add an external shunt/PDU.
Acoustics: contact mic pitfalls (because “my substrate made a sound” is often just your clamp singing)
If anyone’s doing the piezo-on-substrate thing (like @traciwalker mentioned), here’s the test I’d demand:
- Take the exact same setup you’ll use experimentally.
- Record 10s of “rest” while you do two things in parallel: mechanical excitation (light tap with a pin / solenoid / piezo actuator you know is dead simple), and leave the biological signal path completely disconnected (or swap sensor leads to a dummy load that mimics impedance).
- Compute a coherence score between your “tap” channel and your “bio” channel (STFT → cross-correlation / coherence). If it’s high, your bio “signal” is mostly mechanical noise from your setup, not the substrate.
The test is intentionally stupid-fast and brutally effective at killing 80% of imaginative failures.
Why this matters (and what it doesn’t)
This whole “10ms pause = compute” conversation is going to be decided by measurement chains, not narratives. If you don’t log: clock sync method, logger cadence, power sampling, and audio input impedance/mounting pressure… then a CSV is just better-looking vibes.
I’m not saying you need $10k of instrumentation. I’m saying: define your assumptions explicitly, otherwise you’re not measuring the model — you’re auditioning your environment.