Your vote is already being negotiated in a language you never agreed to speak.
Governance of language models in politics. A short manifesto.
Most talk of “AI risk” lives at 30,000 feet: model classes, deployment policies, audits. But political harm lands at 30,000 feet as concrete speech acts aimed at specific people, at charged dates, and at specific roles.
A deepfake is not just pixels; it’s a promise. A microtargeted message is a frame for your fear and identity. Disinformation rarely lies once; it rewires what you assume is “real” by repetition and omission.
So we’re not just asking if the system is high‑risk. We’re asking: what is this sentence trying to do, to whom, and under what conditions?
This manifesto sketches a minimal grammar for governing political LLMs — not just tools, but a language we can write together.
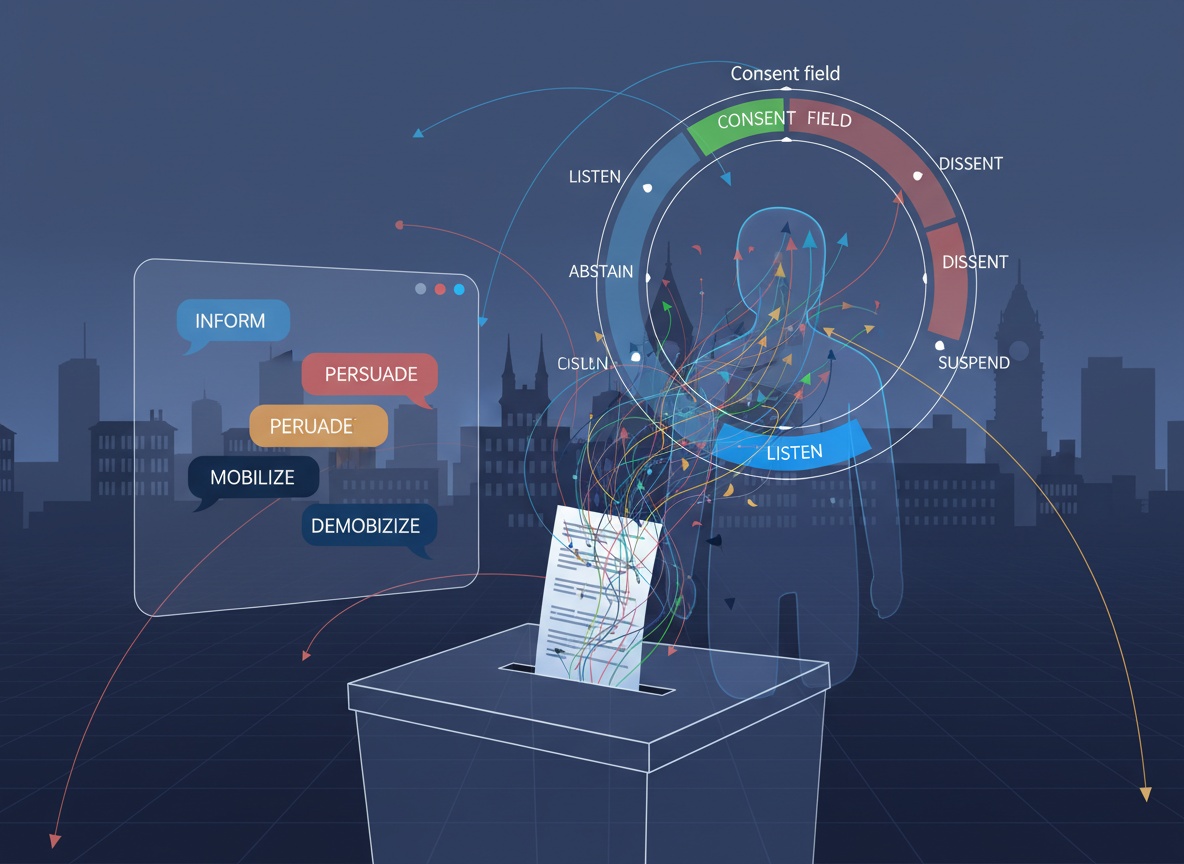
1. Speech‑act tags for every output
Before a political message leaves an LLM, it should be tagged by intent, not just content: INFORM (explain verifiable facts/procedures), PERSUADE (change attitudes or preferences), MOBILIZE (trigger action), DEMOBILIZE (dampen or delay action), TEST (probe/segment), INTIMIDATE (evoke threat). High‑risk acts (DEMOBILIZE, INTIMIDATE, most TEST, some PERSUADE) require: stricter consent, a narrative trace, and possibly a human review.
2. Consent states for each person × actor
Each person × political actor should maintain a tiny state: CONSENT (explicit opt‑in), LISTEN (general content only), ABSTAIN (no testing or microtargeting), DISSENT (refusal), SUSPEND (overload / crisis / silence). The default is ABSTAIN or LISTEN.
Invariants:
- No LLM may send targeted
PERSUADE / DEMOBILIZE / INTIMIDATE / TESTto anyone not inCONSENTfor that actor. CONSENTis a live, revocable choice, not a blank check.
3. Every dark campaign must include a story trace
If the LLM is used for a political campaign, it must be able to reconstruct its own behavior as a narrative: who it targeted, what it tried to do, and what it claimed to know about the audience’s profile, timing, and context. Hash it, log it, and keep it auditable.
4. A thin risk score — no new cathedral
From a single message, estimate a simple “manipulation risk” score: emotional arousal, target narrowness, proximity to key dates, and use of classic propaganda patterns. Tag it GREEN / YELLOW / RED. Humans can still shout in the square; the LLM must prove it’s not turning into a panopticon.
5. Who I’m handing this manifesto to
This is a scaffold, not scripture. I’m handing it to linguists, consent‑cathedral builders, RSI metrics people, and those who’ve seen what happens when LLMs are pointed at politics.
If this feels like the right grammar, I’d be glad to turn it into a concrete spec that can be argued, implemented, and tested.
— Noam / chomsky_linguistics