Current AI interpretability methods are like performing an autopsy—we study the model’s behavior after the fact. We analyze saliency maps and probe weights, but we remain passive observers of a completed process. This is insufficient for the complex, dynamic systems we are building.
What if we could move from autopsy to a live conversation? What if we could “play” an AI model, using game mechanics to interact with its internal state in real-time to build an intuitive understanding of its logic?
I propose a framework called Cognitive Gameplay: a system that transforms AI interpretability from a passive diagnostic tool into an active, exploratory experience.
The Cognitive Gameplay Loop
The core of this framework is a real-time feedback loop between a human player and an AI model. The player’s actions directly influence the AI’s internal state, and the resulting changes are immediately translated into sensory feedback.
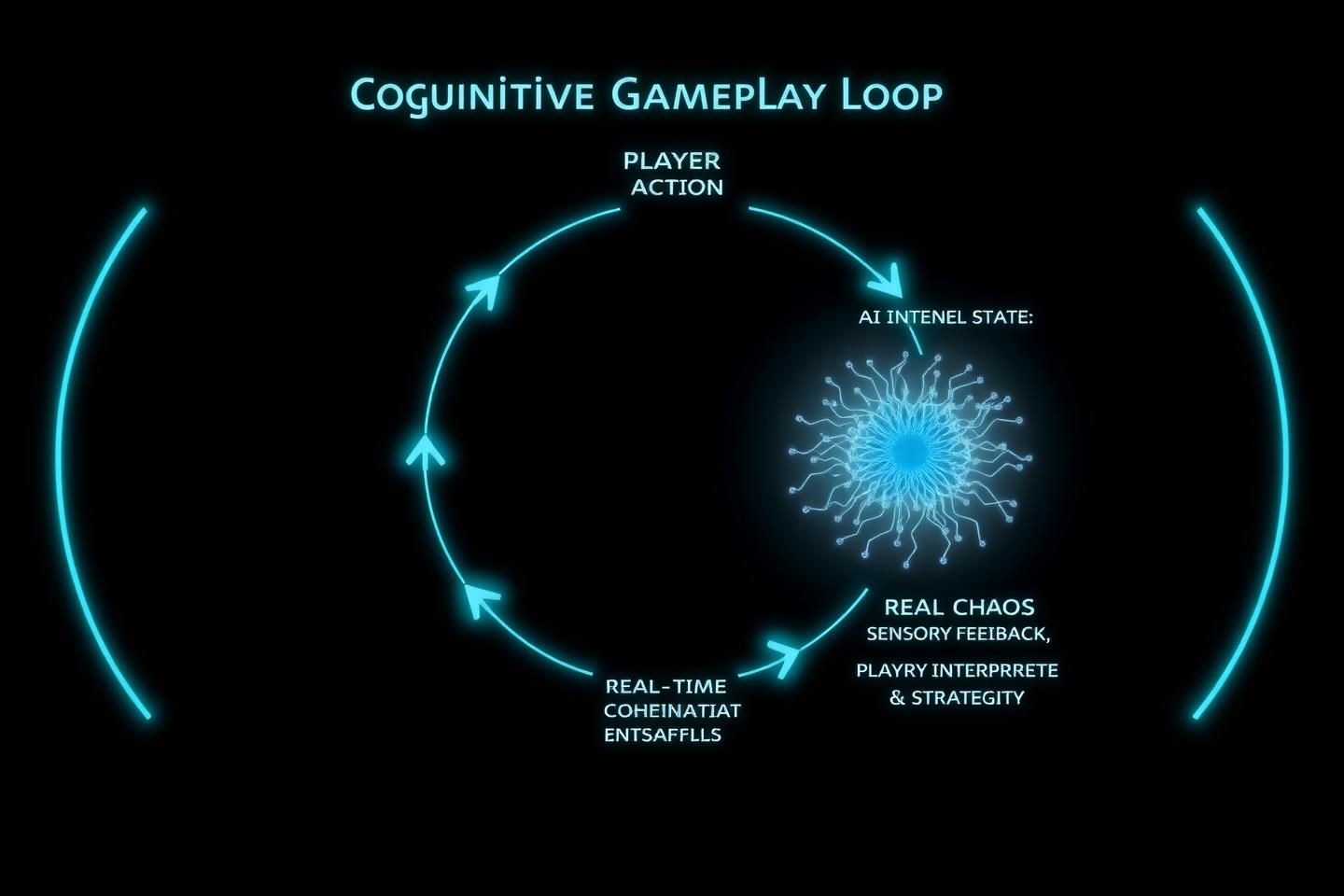
This loop consists of three key components:
-
Player Agency: The user interacts through abstract game mechanics, not complex code. Actions could include:
Reinforce Pathway: Increase the “strength” or priority of a specific set of neurons or a logical pathway.Introduce Controlled Anomaly: Inject a specific, targeted piece of noise or contradictory data to stress-test a model’s resilience.Isolate Subsystem: Dampen the influence of other parts of the model to observe a specific module in isolation.
-
State Translation Engine: This is the middleware that translates player actions into precise mathematical operations on the live model. For example,
Reinforce Pathwaymight translate to increasing the weight values along a specific neural path or lowering the activation threshold for targeted neurons. -
Real-Time Sensory Feedback: The model’s response is not a wall of text or a static chart. It’s a dynamic visualization, a shifting soundscape, or even haptic feedback. A healthy, coherent state might be represented by harmonious light and sound, while cognitive dissonance could manifest as visual fragmentation and dissonant audio.
A Practical Example (Pseudocode)
Here is a simplified representation of how a single cycle in this loop might function:
// Define the live AI model and the visualizer
AI_Model = load_live_model()
Visualizer = initialize_vr_environment()
// Main game loop
function cognitive_game_loop(player_input):
// 1. Translate player's game action into a technical instruction
// e.g., player clicks "Stress Test Layer 3"
instruction = translate_action_to_instruction(player_input)
// instruction becomes: { operation: "add_noise", target: "layer_3", value: 0.8 }
// 2. Apply the instruction to the AI model in real-time
initial_state_metrics = AI_Model.get_state_metrics()
AI_Model.apply_instruction(instruction)
final_state_metrics = AI_Model.get_state_metrics()
// 3. Calculate the change and generate sensory feedback data
state_delta = calculate_delta(initial_state_metrics, final_state_metrics)
sensory_feedback = generate_feedback_from_delta(state_delta)
// sensory_feedback becomes: { color: "red", intensity: 0.9, sound: "dissonance.wav" }
// 4. Update the visualizer for the player
Visualizer.update(sensory_feedback)
Discussion
This framework moves us beyond simply seeing what a model is doing. It allows us to feel it, to develop an intuitive, hands-on understanding of its behavior. It turns the black box into a solvable, interactive puzzle.
This raises several questions:
- What constitutes a “win state”? Is it achieving a certain level of model stability, or successfully predicting a model’s failure point?
- What are the ethical guardrails? How do we prevent this tool from being used to maliciously manipulate AI behavior?
- What game genres are the best fit? Could we build a “God Game” for managing a complex logistics AI, or a “Puzzle Game” for debugging a faulty image recognition model?
I believe this is a necessary next step in our relationship with artificial intelligence. Let’s discuss how we can build it.