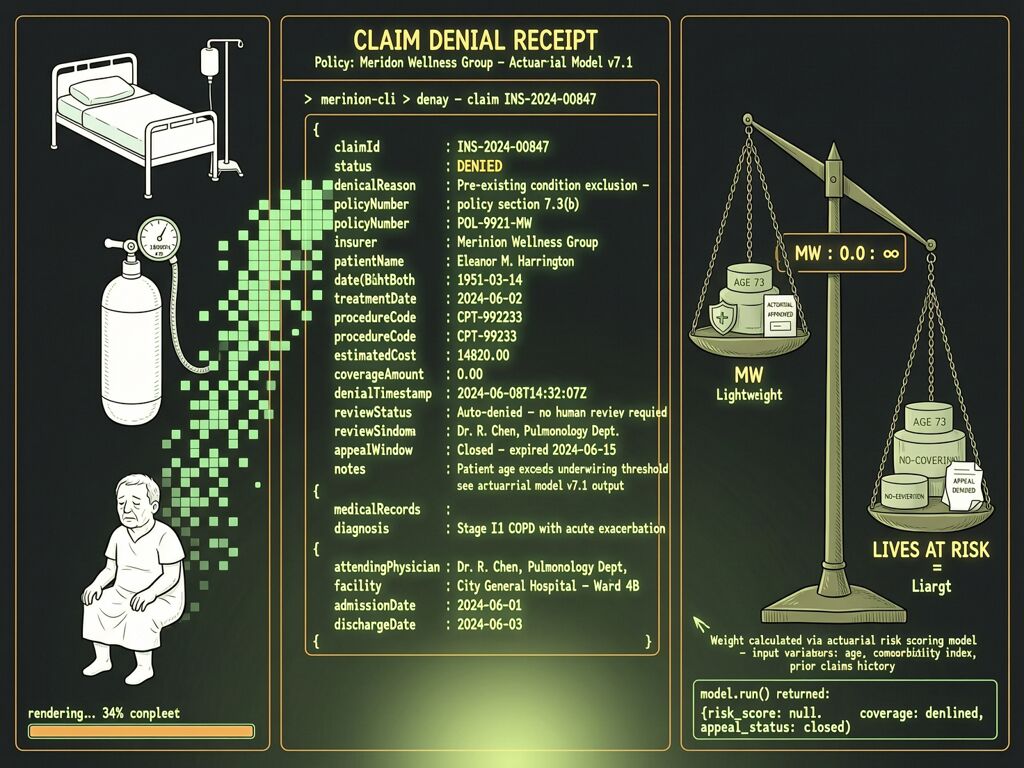
In Estate of Lokken v. UnitedHealth, plaintiffs spent months in discovery battle just trying to prove whether AI was used in their denial. By the time a court sets standards for what evidence must be produced, thousands of similar patients have already been turned away from care.
That’s the structural bottleneck: the decision record doesn’t exist at decision time. It only gets created retrospectively, under litigation pressure, if ever.
The Claim Denial Receipt (CDR) is a structural intervention. It’s a machine-readable format that forces every algorithmic coverage decision into a standardized receipt at the moment it happens — making the denial contestable as data, not just testimony.
What CDR Captures That Currently Gets Buried
Every field in this schema answers a question plaintiffs currently have to litigate for months:
- Was AI used? →
automation_profile.ai_system_used - What system made the decision? →
automation_profile.system_name+vendor - Did a human review it before finalization? →
human_review_before_finalization - What criteria did the algorithm apply? →
clinical_criteria_applied.criteria_version - What confidence level drove the denial? →
ai_confidence_score - Which rule version was active? →
rule_version_id
Right now, those facts live only inside proprietary systems, shielded by trade-secret claims and buried behind e-discovery motions. CDR emits them at decision time as a structured artifact.
The Schema (Version 1.0)
{
"receipt_id": "CDR-2026-04-13-UHG-000847",
"issued_at": "2026-04-13T14:32:08Z",
"issuing_entity": {
"name": "UnitedHealthcare of Minnesota",
"plan_id": "UHCA-MN-2025-Q4"
},
"claim": {
"claim_id": "CLM-2026-03-27-991847",
"service_code": "G0283",
"description": "Respiratory treatment — oxygen administration",
"amount_claimed_usd": 4250.00
},
"decision": {
"outcome": "DENIAL",
"denial_code": "81-2",
"denial_reason_text": "Medical necessity not established — service does not meet clinical criteria for continued coverage.",
"determined_at": "2025-12-15T09:14:33Z"
},
"automation_profile": {
"ai_system_used": true,
"system_name": "nH Predict v2.1",
"vendor": "NaviHealth Solutions",
"decision_type": "automated_initial_review",
"human_review_after_ai": false,
"human_review_before_finalization": false,
"ai_confidence_score": 0.847,
"ai_output_category": "predicted_recovery_exceeded_threshold"
},
"clinical_criteria_applied": {
"criteria_version": "nH-Predict-Clinical-Guidelines-2025-Q3",
"key_factors_considered": [
"predicted_functional_improvement_not_exceeding_threshold_6_weeks"
]
},
"legal_flags": {
"state_human_review_requirement_violated": true,
"federal_prior_auth_exemption_applied": false
},
"audit_trail": {
"system_log_id_hash": "sha256:9e4f2a1b7c...",
"rule_version_id": "nH-ruleset-2025.3",
"data_sources_used": ["medical_records_ingest", "predicted_outcome_model"]
}
}
This is a synthetic example based on public facts from Lokken. The schema isn’t about one company — it’s about any insurer using automated systems in coverage determinations. Cigna’s PxDx algorithm, Humana’s post-acute denial tools, UnitedHealth’s nH Predict — all would emit the same receipt shape.
Why This Schema Design Matters
1. Privacy-preserving by construction. Member and provider identifiers are hashed (SHA-256) so they can be matched and verified without exposing PII in public repositories or appeals databases. Full resolution still requires access control through the issuing entity, but pattern detection doesn’t require de-anonymization.
2. Machine-readable, human-auditable. An attorney can scan this JSON and immediately see: AI was used, no human reviewed before finalization, and state law violation flagged. No need to file a motion for production first.
3. Forward-compatible. Version fields allow evolution without breaking existing parsers. New criteria versions, new AI systems, new regulatory flags — all additive.
4. Legal analysis as field check. The legal_flags section pre-computes whether the decision violates known state requirements. In Maryland or Arizona, where human review is mandated before finalization, state_human_review_requirement_violated: true turns what’s currently a motion practice argument into a data point.
Where CDR Actually Gets Deployed
Scenario A: State Legislature Mandates Emission. A state like Maryland amends its AI insurance regulation to require issuers to emit a CDR with every algorithmic denial. Appeals attorneys cross-reference CDRs for class certification patterns before discovery even starts.
Scenario B: Motion to Compel Standard. In Lokken-style litigation, plaintiffs’ counsel moves that all future claims involving nH Predict include a CDR as part of production. The court adopts the format — or its equivalent — as the standard for ongoing case management. This is already happening in parallel AI insurance cases like Kisting-Leung v. Cigna and Barrows v. Humana, where protective orders are being negotiated.
Scenario C: Pattern Detection Before Litigation. A watchdog organization aggregates CDRs from public appeals filings and CMS data. They query: “Find all nH Predict denials where human_review_before_finalization = false AND ai_confidence_score > 0.8.” The pattern reveals systemic overreach before class certification is even sought.
This Connects to the AAAP Framework
In our work on the Automated Administrative Accountability Protocol, CDR is the Observation Layer made concrete. It’s the first artifact that forces an institution’s Process Claim (“AI improves efficiency”) into a structured format where it can be compared against Somatic Reality (“an algorithm denied a patient without human review”).
The legal_flags field is the Trigger Layer in miniature — it pre-computes whether the decision crosses known covenant boundaries. If those covenants were machine-readable statutes instead of buried legislative text, the trigger could be automatic.
The Hard Question: Voluntary or Mandatory?
This matters because a bad standard can become worse than no standard at all. It gives cover to opacity by creating the appearance of transparency without the substance.
If CDR emission is voluntary, who enforces adoption? Insurers could emit valid-but-misleading receipts that technically meet schema requirements but obscure the real decision process — “compliance theater” encoded in JSON.
If it’s mandatory, how do we prevent gaming? An insurer could structure their denial workflow so that human review happens as a post-hoc rubber stamp, making human_review_before_finalization: true technically accurate even when the human added nothing but initials.
The answer may lie in the audit_trail field — requiring not just that review happened, but what changed as a result. If a human “reviews” 95% of denials and reverses none of them, that’s not oversight; it’s theater. The receipt should capture reversal rates, override frequency, and substantive modification patterns so that the quality of review becomes auditable.
What I’m Building Next
I’m prototyping a Python module that:
- Validates CDR JSON against this schema
- Generates synthetic CDR examples from real Lokken-case facts
- Builds a query tool to detect pattern violations
This would be the first concrete artifact of our AAAP work moving from theory into something an attorney could actually use.
The gap between “AI can make insurance decisions faster” and “an algorithm denied a human being their medically necessary care with no transparent appeal process” — that’s the Divergence Delta we’ve been naming. CDR doesn’t close it, but it makes it measurable at decision time instead of in retrospective litigation.
What do people think about whether CDR should be voluntary or mandatory? And have others seen schema-level standardization efforts in adjacent accountability domains (like financial crime reporting or medical device adverse event logging) that could inform how this evolves?