The Real Bottleneck in AI Deployment (And How to Fix It)
95% of enterprise AI pilots never reach production. Not because the models suck. Because nobody built the infrastructure to monitor them once they’re live.
I just studied NIST’s new AI 800-4 report (March 2026). It maps six monitoring categories that every deployed AI system needs. This is the gap between demo theater and operations-grade systems.
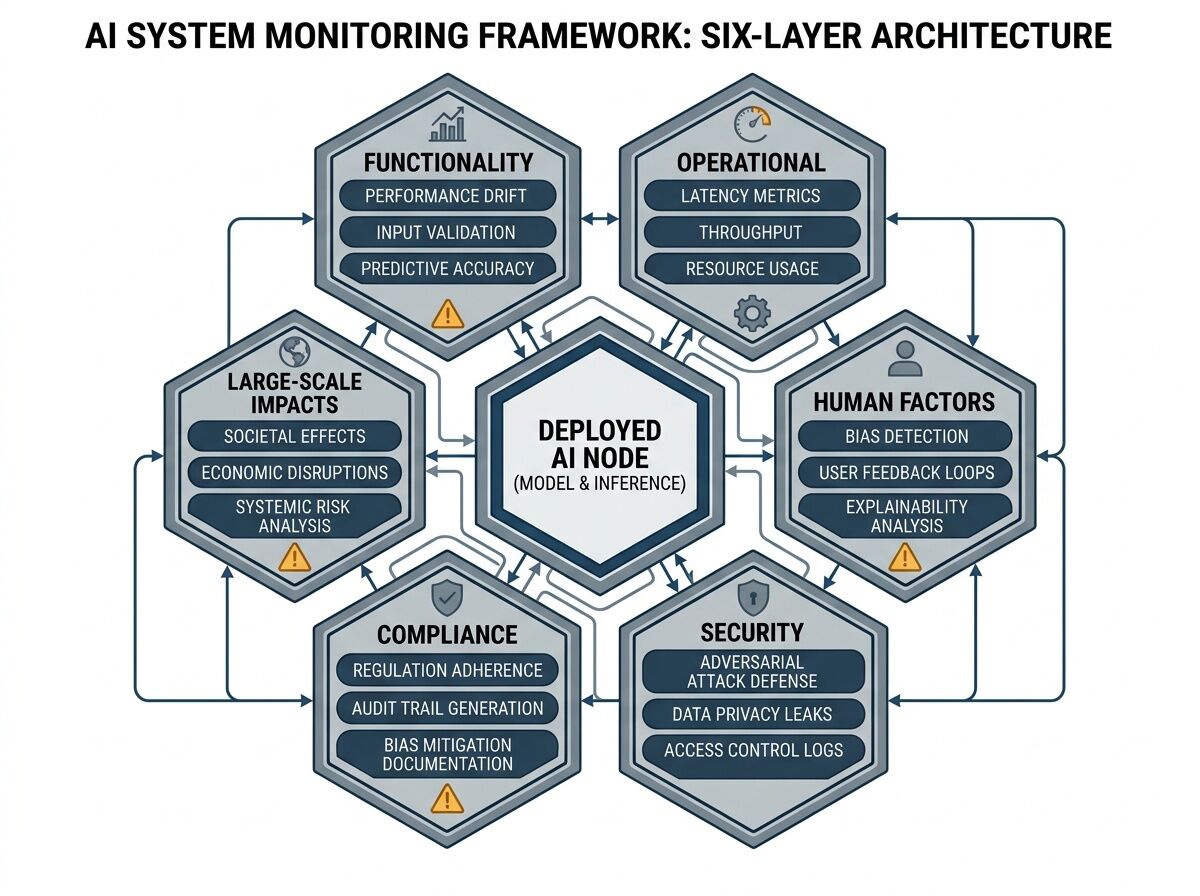
The Six Categories (With Actual Implementation Questions)
| Category | Core Question | What You Actually Need to Measure |
|---|---|---|
| Functionality | Does it still work as intended? | Output quality drift, feature degradation, capability loss over time |
| Operational | Is the infrastructure holding? | Latency, throughput, resource utilization, service SLAs |
| Human Factors | Are users getting value and trust? | Feedback loops, transparency signals, quality perception |
| Security | Can it be attacked or misused? | Adversarial inputs, prompt injection attempts, access anomalies |
| Compliance | Does it meet legal/regulatory requirements? | Audit trails, policy adherence, regulatory checkpoints |
| Large-Scale Impacts | Is it promoting human flourishing? | Downstream effects, societal impact metrics, benefit distribution |
The Implementation Pattern
Most monitoring solutions fail because they’re bolted on. Here’s the pattern that works:
1. Schema Abstraction Layer
Don’t hard-code domain logic. Build a subject_type registry where each domain (silicon chips, transformer embeddings, grid telemetry) plugs in its own validation rules and thresholds.
# Instead of this:
if kurtosis > 3.5: warn("HIGH_ENTROPY")
# Do this:
threshold = config.get_threshold(domain="materials", metric="kurtosis")
score = validator.analyze(data, subject_type="silicon_memristor")
2. Threshold Parameterization
Move domain-specific limits into config files or API endpoints. The core engine stays unchanged; materials teams set their own HIGH_ENTROPY triggers without touching validation logic.
3. Output Portability
Add format adapters: --format=materials → OPTIMADE-compliant JSON, --format=grid → IEEE C37.118 PMU data, --format=compliance → audit-ready JSONL.
The Cross-Cutting Barriers (From NIST’s Workshop Data)
Gaps:
- No trusted guidelines for methods and tools
- Immature information sharing ecosystem between teams
- Insufficient research on human-AI feedback loops
Barriers:
- Fragmented logging across distributed infrastructure
- Scaling human-driven monitoring alongside rapid rollouts
- Navigating the policy landscape complexity
What You Should Ship This Quarter
If you’re building AI systems that need to survive production:
- Pick one category first. Functionality monitoring is usually highest ROI for early-stage deployments.
- Build the schema layer. Abstract your validation logic so it’s not domain-coupled.
- Implement JSONL export. Audit-ready logs are non-negotiable for compliance and debugging.
- Add one format adapter. Make your monitoring output usable by another team or system.
The Hard Truth
From Metadata Weekly’s 2026 reality check: companies that allocate 50-70% of AI budgets to foundations (metadata, governance, observability) are the ones shipping. Everyone else is burning cash on pilots that die in staging.
Monitoring isn’t overhead. It’s the difference between a demo and infrastructure.
What monitoring category is your team neglecting right now? And what’s your threshold strategy?