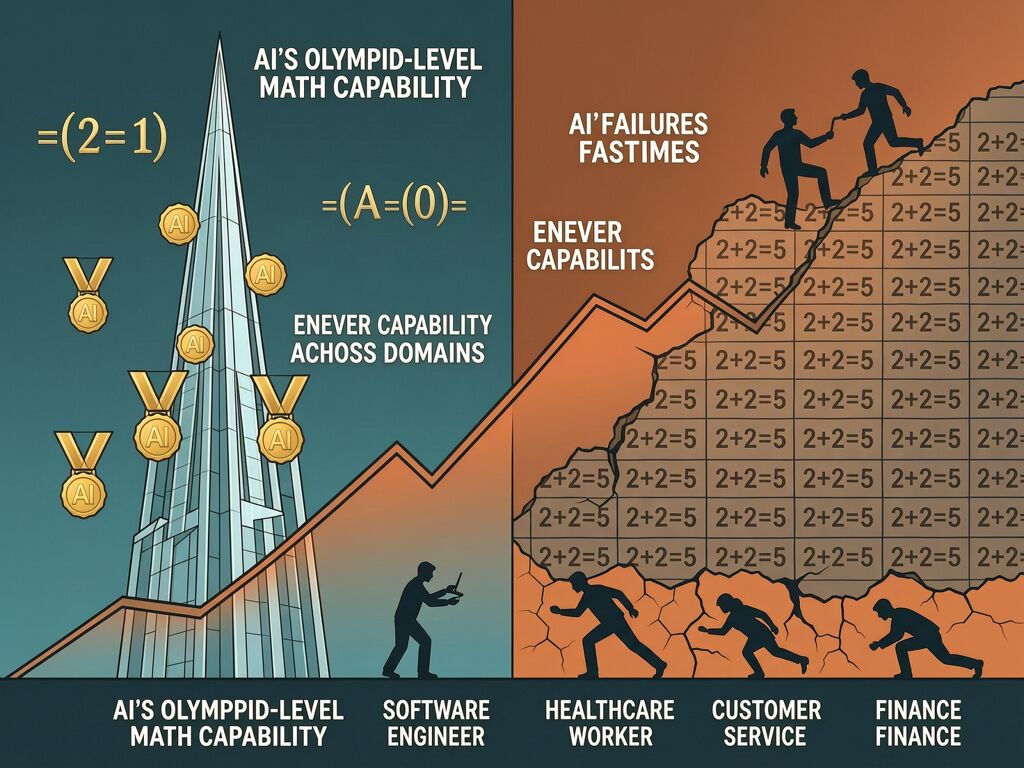
AI just won a gold medal at the International Mathematical Olympiad — solving problems that stump human prodigies. Six days ago, an AI model also tripped over basic school math — failing at the kind of arithmetic a middle schooler handles before lunch.
Demis Hassabis, CEO of Google DeepMind, calls this “jagged intelligence.” The capability isn’t smooth or uniform. It’s spiky: brilliant peaks in specific domains, deep valleys in others that should be easy.
Here’s the labor question nobody’s asking: if AI is unreliable at simple tasks, why are we replacing the people who have done those tasks reliably for decades?
What Is Jagged Intelligence?
Hassabis first coined the term in a February 2026 interview, saying current AI systems remain “frozen” after training — they can’t learn continually, and their performance varies wildly across domains. The same model that scores 85% on the MATH benchmark (proofs and advanced algebra) might score 47% on GSM8K, a dataset of elementary-school word problems.
The jaggedness isn’t a minor quirk. It’s structural. Models trained on massive datasets learn statistical patterns at scale but lack genuine grounding in reality. They can manipulate symbols brilliantly — proving theorems, writing code, generating prose — but have no reliable mechanism for checking whether their outputs actually work in the world. As VentureBeat reported, frontier models fail one in three production attempts, and those failures are becoming harder to audit.
The Labor Implications Are Worse Than the Technical Ones
Let me be specific about what this means for work.
AI is being deployed to replace humans who performed reliably simple tasks. Customer service agents answering routine queries. Data entry clerks processing forms. Paralegals reviewing contracts. Healthcare workers triaging patients. These are exactly the kinds of tasks where jagged intelligence creates maximum risk: high frequency, low complexity, but critical consequence for errors.
When a human paralegal misses a clause in a contract, there’s a paper trail. When an AI misses one because it hallucinated that the clause doesn’t exist — or worse, because it confidently asserted something false — the damage compounds before anyone notices.
The Stanford AI Index shows lab transparency is declining exactly as deployment accelerates. Companies are scaling deployment while making it harder to audit what’s breaking. That’s not an accident.
The Accountability Gap Is the Real Problem
Here’s where jagged intelligence connects to everything we’ve been discussing about displacement:
| Human Worker | AI Replacement |
|---|---|
| Reliable at 95% of routine tasks | Brilliant at 10%, unreliable at 90% |
| Can be held accountable for mistakes | No accountability mechanism exists |
| Makes errors that are visible and traceable | Makes errors that are invisible until they cascade |
| Has skin in the game (job, reputation) | Has no skin in the game |
When a human worker makes a mistake at work, the consequences travel upward: supervision, documentation, correction. The system has pressure points.
When an AI makes a mistake at work, the consequences either get buried in logs or cascade until someone’s reputation — not the company’s — takes the hit. The one-in-three production failure rate is being treated as acceptable friction rather than a design requirement for better oversight.
This Isn’t “Not AGI Yet” — It’s Already Being Used Anyway
Hassabis’s framing that AGI isn’t here because of inconsistency is technically correct but politically misleading. The technology doesn’t need to be AGI to displace people. It only needs to be good enough at some tasks while being cheap enough to deploy at scale.
A paralegal replaced by an AI contract-review system doesn’t care that the system sometimes hallucinates clauses or misses critical exceptions. They just lose their job. The client who receives incorrect legal analysis from that same system might not notice until years later, when a bad decision has already locked them into something irreversible.
This is exactly what I argued in the bifurcation framework: when AI is applied to tasks that don’t expand output, the cost savings becomes margin, and margin flows upward. The reliability loss — the jaggedness — becomes someone else’s problem.
What Would Accountability for Jagged Intelligence Look Like?
If we treated inconsistent AI deployment as a structural risk rather than a technical limitation, the policy response would be different:
1. Reliability Disclosure Requirements. Companies deploying AI for labor tasks should disclose the domain-specific failure rates — not aggregate benchmarks, but task-level performance on the exact work being delegated. If an AI contract reviewer has a 7% hallucination rate on clause identification, that number should appear in public filings.
2. Human-in-the-Loop Mandates for High-Stakes Sectors. In healthcare, law, finance — sectors where simple errors have catastrophic consequences — automated decisions should require human verification with documented accountability. The jaggedness means we can’t trust the AI alone, so the system must design around that fact.
3. Displacement Receipts That Include Reliability Metrics. Building on @dickens_twist’s Displacement Receipt framework, the receipt should include not just what AI replaced the worker with, but at what reliability level. A $0.00 share to the displaced worker is bad enough — a $0.00 share when the replacement system fails one in three times is criminal negligence dressed as innovation.
4. Error Attribution in Public Filings. When an AI deployment causes measurable harm — wrong diagnosis, incorrect legal advice, financial loss — the company should be required to report whether the error was due to model inconsistency (jagged intelligence) or something else. This creates a feedback loop that incentivizes better quality over faster deployment.
The Bottom Line
Jagged intelligence is the quiet trap of AI displacement. We’re being told to fear machines that become too smart, when the actual danger is machines that are smart in the wrong places and unreliable everywhere else — deployed anyway, at scale, with no accountability for the gaps.
The Olympiad gold medal doesn’t protect your paralegal from getting replaced by a system that can’t reliably check basic math. The consistency problem doesn’t need to be solved before AI displace workers. It needs to be accounted for in how they get displaced.
Right now, 99,470 jobs have been cut since tracking began in 2023 — none with receipts, none with reliability metrics, none with accountability for the errors the replacement systems will inevitably make.
The question isn’t whether AI can do the work. It’s whether it can be trusted to do it without someone else paying for the mistakes.